





熟悉的感觉又来了——AI一天,世间一年。今年开年以来,AI领域的蓝驰家族成员们时不时就会跟我们分享推出新品的好消息。从基础模型到AI Agent、再到具身智能模型等,我们真切感受到智能的生长正在加速。所以我们收集了近期蓝驰家族成员们推出的AI领域新产品,带给你AI创新的前沿快报。新产品太多了,挂一漏万,欢迎自行探索、持续关注蓝驰家族——

3月27日,李想首次展示并发布「理想星环OS」的开源成果。这是全球首家将汽车操作系统开源的汽车企业,整体性能全面超越行业头部闭源AUTOSAR操作系统。相较于闭源操作系统,理想星环OS芯片适配周期缩短至四周内,全面支持市场上所有车用芯片架构,真正实现了芯片选择的自由。理想星环OS作为AGI时代的汽车操作系统,集成毫秒级实时控制、高算力自动驾驶及智能交互等多样化功能,实现了跨领域软硬件深度协同与双重安全保障。
就在十天前,理想汽车发布新一代自动驾驶架构MindVLA,成功整合了空间、语言与行为智能,将把汽车从单纯的运输工具转变为贴心的专职司机,能听得懂、看得见、找得到。
对于用户来说,MindVLA 让车不仅仅是车,而是一个能听懂你说话、看懂你需求、帮你解决问题的“专职司机”。

MindVLA 模型加持下的汽车就像一个助手,能与用户沟通、理解用户意图,帮用户做更多事情。例如,它可以在陌生车库漫游找车位直至自主完成泊车;可以按照驾驶员的“开快点、开慢点、左拐、右拐”等语音指令进行行动;可以在你发给它地标照片后,按图索骥找到你等等。

月之暗面Kimi团队在1月发布了k1.5 多模态思考模型。这是继去年11月发布 k0-math 数学模型,12月发布 k1 视觉思考模型之后,Kimi 连续三个月带来 k系列强化学习模型的重磅升级。

本次发布的k1.5 模型具备独特的多模态(文本、视觉)联合训练架构,技术测试显示,在short-CoT模式下,该模型在数学、代码、视觉多模态和通用能力大幅超越GPT-4o和Claude 3.5 Sonnet。在long-CoT模式下,数学、代码与多模态推理能力更是追平OpenAI o1正式版,成为全球首个非OpenAI体系达到该性能标准的多模态推理模型。
Kimi 团队发布的详细技术报告中,提到了关于k1.5 模型设计和训练的几个关键点:《Kimi k1.5:借助大语言模型实现强化学习的 Scaling》(GitHub链接: https://github.com/MoonshotAI/kimi-k1.5 )

3月10日,智元机器人发布首个通用具身基座模型——智元启元大模型(Genie Operator-1),开创性地提出了Vision-Language-Latent-Action (ViLLA) 架构。
该架构由VLM(多模态大模型) + MoE(混合专家)组成,其中VLM借助海量互联网图文数据获得通用场景感知和语言理解能力,MoE中的Latent Planner(隐式规划器)借助大量跨本体和人类操作视频数据获得通用的动作理解能力,MoE中的Action Expert(动作专家)借助百万真机数据获得精细的动作执行能力,在推理时,三者协同工作。
GO-1大模型让机器人获得了颠覆性的学习能力,并且可以泛化应用到不同的环境和物品中,快速适应新任务、学习新技能。同时,它还支持部署到不同的机器人本体,高效地完成落地,并在实际的使用中持续不断地快速进化。更多技术细节可参考:
《VLA进化到ViLLA,智元发布首个通用具身基座大模型GO-1》
3月18日,智元团队进一步提出全新的数据采集范式ADC (Adversarial Data Collection, 对抗数据采集),大幅提升了数据的信息密度和多样性。在降低了训练成本的同时提升了模型的鲁棒性和泛化性,与传统范式相比,使用20%数据量达到其2.7倍的效果。
论文地址:https://arxiv.org/abs/2503.11646
项目地址:https://sites.google.com/view/adc-robot/home


银河通用机器人近期联合北京智源人工智能研究院(BAAI)及北京大学和香港大学研究人员发布了GraspVLA模型——全球首个端到端具身抓取基础大模型。

GraspVLA 的训练包含预训练和后训练两部分。
其中预训练完全基于合成大数据,训练数据达到了有史以来最大的数据体量——十亿帧「视觉-语言-动作」对,掌握泛化闭环抓取能力、达成基础模型;预训练后,模型可直接 Sim2Real 在未见过的、千变万化的真实场景和物体上零样本测试,全球首次全面展现了七大卓越的泛化能力,满足大多数产品的需求;而针对特别需求,后训练仅需小样本学习即可迁移基础能力到特定场景,维持高泛化性的同时形成符合产品需求的专业技能。
什么是真正的泛化?本次,银河通用给出了 VLA 达到基础模型需满足的七大泛化金标准:光照泛化、背景泛化、平面位置泛化、空间高度泛化、动作策略泛化、动态干扰泛化、物体类别泛化。上述七点GraspVLA均能做到。
同时, GraspVLA 还能具备对新需求的快速适应及迁移能力:迅速服从指定规范并“举一反三”、迅速掌握新词汇,拓展新类别、迅速对齐人类偏好。

3月3日,灵初智能发布了基于强化学习的增强版分层架构端到端 VLA 模型 Psi R0.5,这距离公司团队去年底发布的 Psi R0 仅 2 个月。本次发布的新模型在复杂场景的泛化性、灵巧性、CoT、长程任务能力上均有显著提升,同时完成泛化抓取训练所需的数据量仅需 Helix 数据量的 0.4%,在全球范围内实现了泛化灵巧操作与训练效率的双重领先。
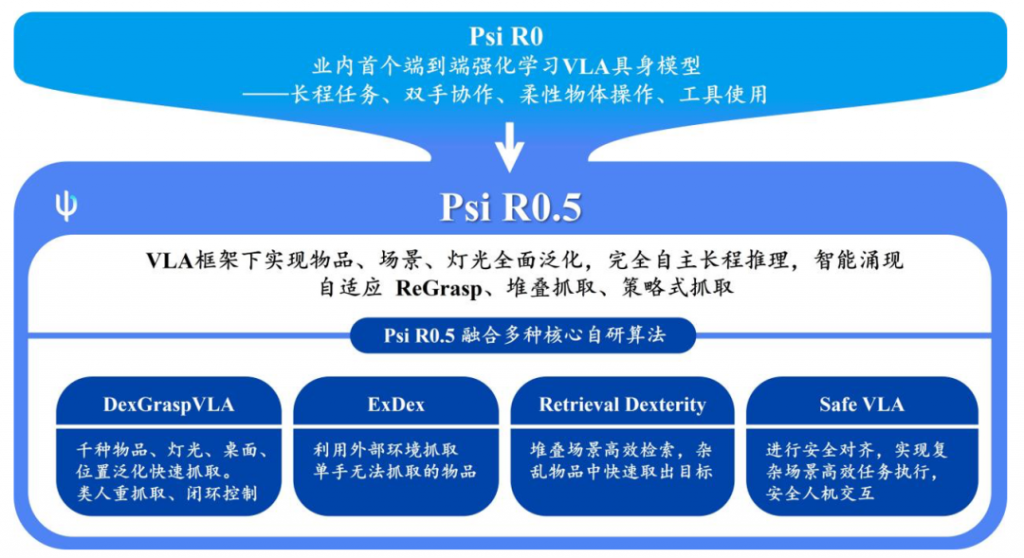
Psi R0.5融合了四种核心自研算法:

3月31日,由优艾智合与西安交通大学联合创立的具身智能机器人研究院首次对外公布团队打造的人形机器人矩阵,并亮相其中一款轮式人形机器人——巡霄。
「天演」系列共包含7款产品,根据应用场景的差异形成不同的机器人定位,涵盖双足、轮式、四足、履带式等形态。其中,「巡霄」针对大面积复杂室内场景,拥有长续航和高灵活性的特点,已应用于半导体制造Sub-FAB运维及能源行业配电间操作等领域。

基于场景适应性特征,团队构建了“一脑多态”的具身智能大模型,采用多模态通用基座大模型+“一脑多态”端侧具身模型的混合架构,并完成场景应用初步验证。

听力熊TeeniAI基于“AI agent”(智能体)这一概念,构建了面向4-14岁用户的“专属随身智能体”硬件产品系列。 至2024年,听力熊产品累计激活量已经超过50万台,月留存超过55%,已成为通义等大模型调用量最大的青少年终端。
在听力熊产品中,团队设计了一整套围绕儿童成长的AI系统。除了听书、学习等场景,听力熊可以记录用户的成长事件,形成独属于这个用户的记忆系统,家长端则可以定期查看周报,来提升亲子互动效率。在大模型浪潮来临后,听力熊团队发现青少年对AI陪伴的需求大大加强,快速迭代推出X系列,定位是更高阶的“AI伙伴”,基于内置的TeeniGPT,孩子可以即拍即问,进行创意创作。
2025年,听力熊将推出面向全球市场的新品Pocket Robot,增强多模态能力,支持多视角摄影记录与实时翻译。


今年1月,即时设计全面升级「全球首个 AI 网站团队」Wegic.ai,只需下达指令,三位 AI 员工时刻待命为你服务,满足你的各种需求。
网址:https://wegic.ai/
看看他们如何让你的网站创建&运营变得轻而易举:
截至目前,Wegic 的用户已遍布全球 226+ 国家和地区,帮助用户创建并管理 500,000+ 网站。并在全球最大的产品社区 Product Hunt 2024年度产品评选中,荣获No Code赛道的亚军。

跃然创新的首款AI硬件产品「BubblePal」在抖音、小红书等新电商平台都取得了远超内部预期的首发成绩。
BubblePal 基于 AI 原生和自研的情绪模型,为毛绒玩具提供与儿童的互动对话能力,用 AIGC 回应孩子的每一个奇思妙想。BubblePal 融合软硬件,硬件外形选用了带有童真色彩的“魔法泡泡”,当毛绒玩具佩戴上泡泡时,它就被赋予了能思考、对话的能力,可进行双向互动。

为了让产品更聪明、更契合儿童陪伴场景,在技术路线上,跃然创新采用大模型+小模型的双层模型思路,大模型提供生成和逻辑推理能力,小模型提供情绪价值。
目前,BubblePal 已接入字节跳动自研豆包大模型,可实现复杂文本理解、角色扮演、语音对话等功能。同时,依托火山方舟平台提供的推理算力资源和完整工具链,将生成式AI模型能力植入玩具,产生新的交互内容。

今年初,可以科技的宠物机器人Loona学会了一项新技能:双Loona互动,只需要将两只Loona连接到同一个App,通过SN号进行配对,即可激活互动功能。同时配备记忆功能,每次配对内容都会被自动保存,确保你和你的Loona能够持续享受专属互动。

在生成式AI技术逐渐成熟的当下,可以科技的第二代产品、陪伴机器人Loona将功能重点放到了人机交互。“我们想通过Loona打造下一代机器人智能决策机(Intelligent decision making machine)通过智能决策机,可以让机器人能够通过多模态信息流畅地表达情感,让机器人真正懂人。”


当传统金融科技仍在优化交易算法时,RockFlow以革命性产品Bobby重新定义投资边界——全球首个具备情绪感知能力的金融AI Agent。这款智能体突破传统交易机器人模式,构建起涵盖市场情绪监控、个性化策略生成、动态风险管理的三维能力体系,将自然语言交互深度融入投资决策全流程。
Bobby的核心创新在于建立“语义-策略-执行”的智能闭环。用户通过自然语言描述投资意向,系统实时解析全球市场情报(涵盖新闻舆情、社交媒体声量、财报数据等多源信息),自动生成适配个人风险偏好的投资方案,并完成无缝交易执行。这种”思考-行动”链路的压缩,使得从意图输入到订单落地的转换效率较传统系统提升三个数量级。